# packagespacman::p_load( tidyverse, # data import and handling conflicted, # handling function conflicts emmeans, multcomp, multcompView, # adjusted mean comparisons ggplot2, effectsize, # effect size calculation desplot, # for plotting experimental designs rstatix, ggdist, performance, see) # plots
package 'rstatix' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\sithj\AppData\Local\Temp\RtmpMnOMHd\downloaded_packages
# conflicts between functions with the same nameconflict_prefer("filter", "dplyr")conflict_prefer("select", "dplyr")
Data
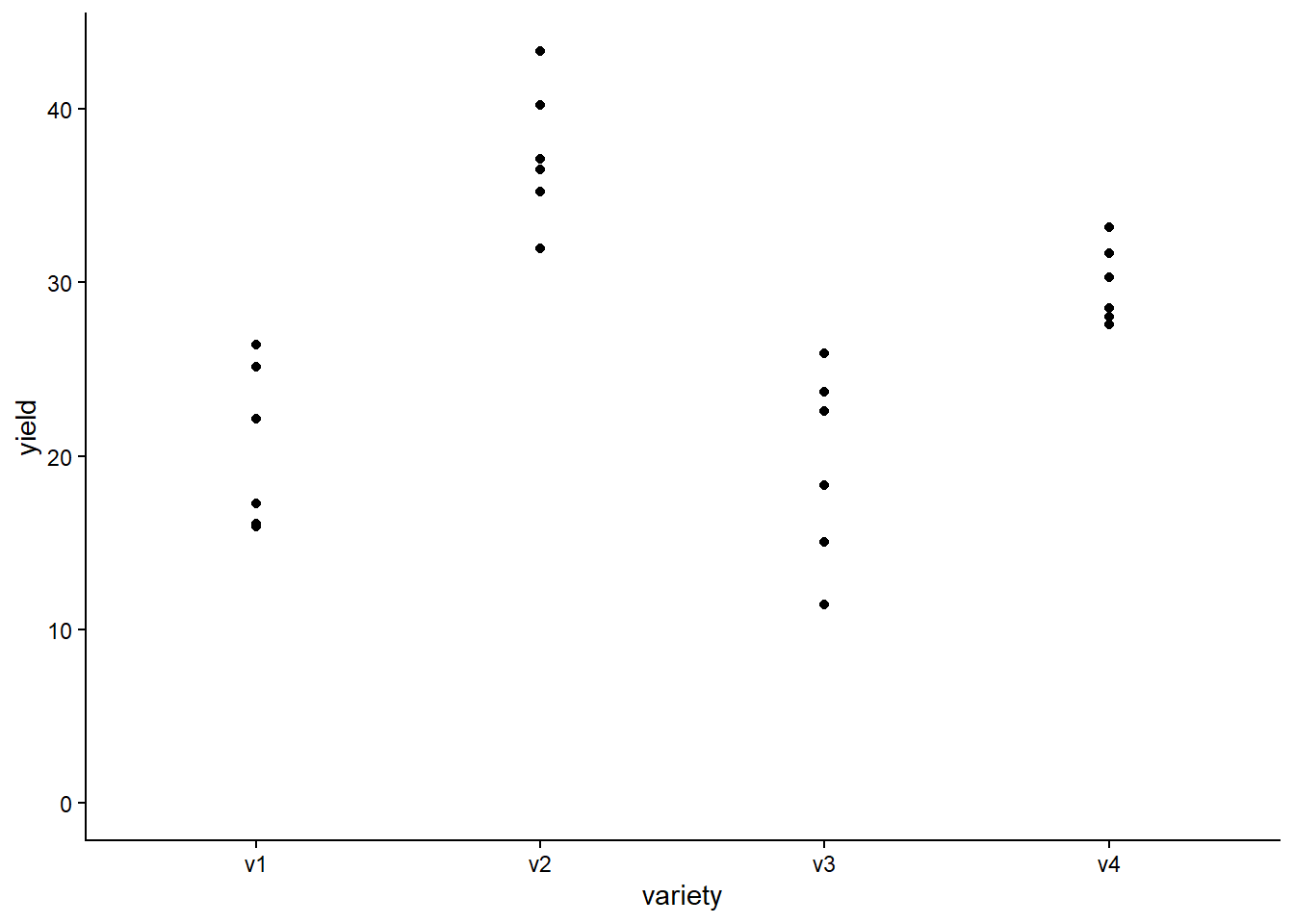
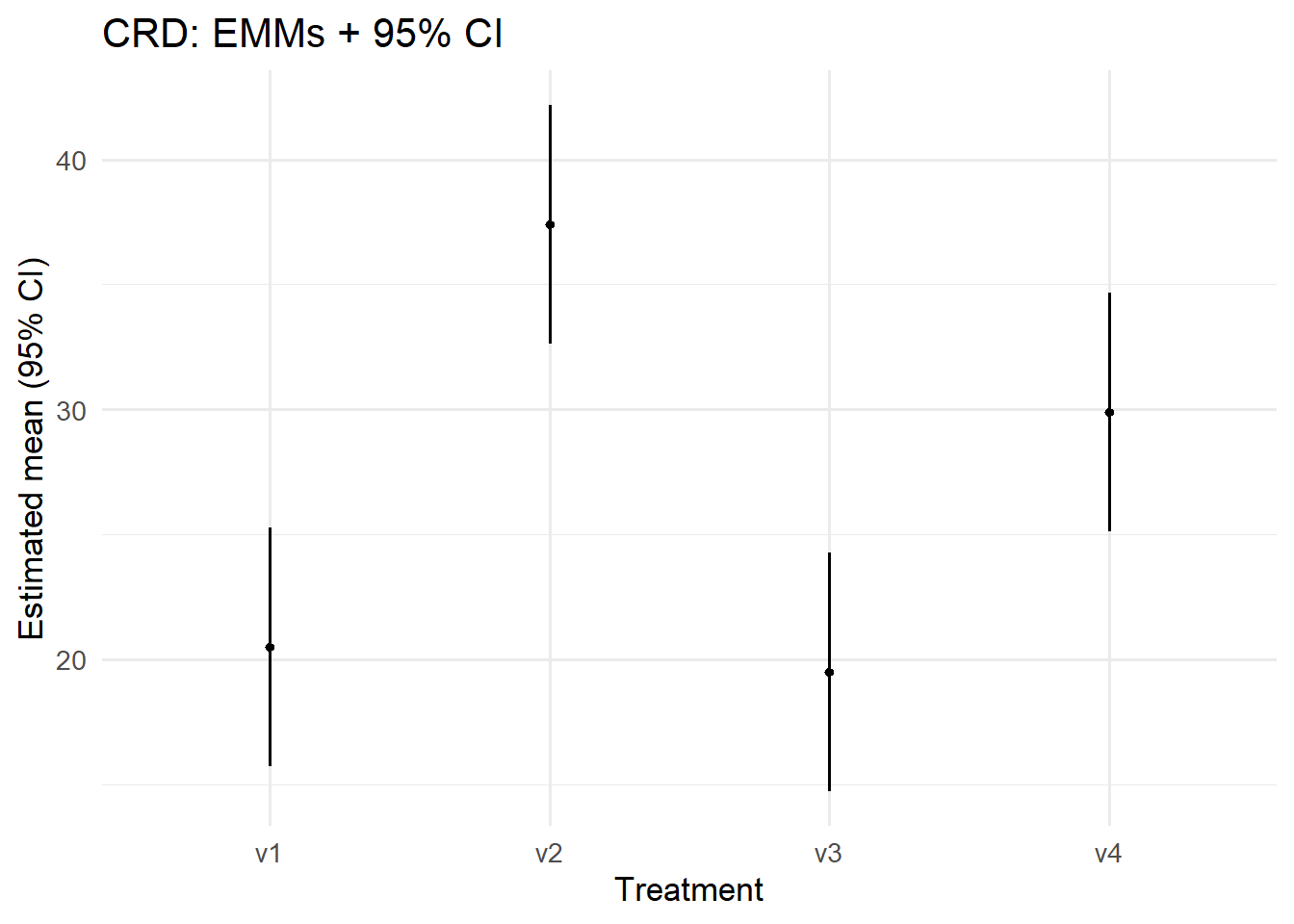
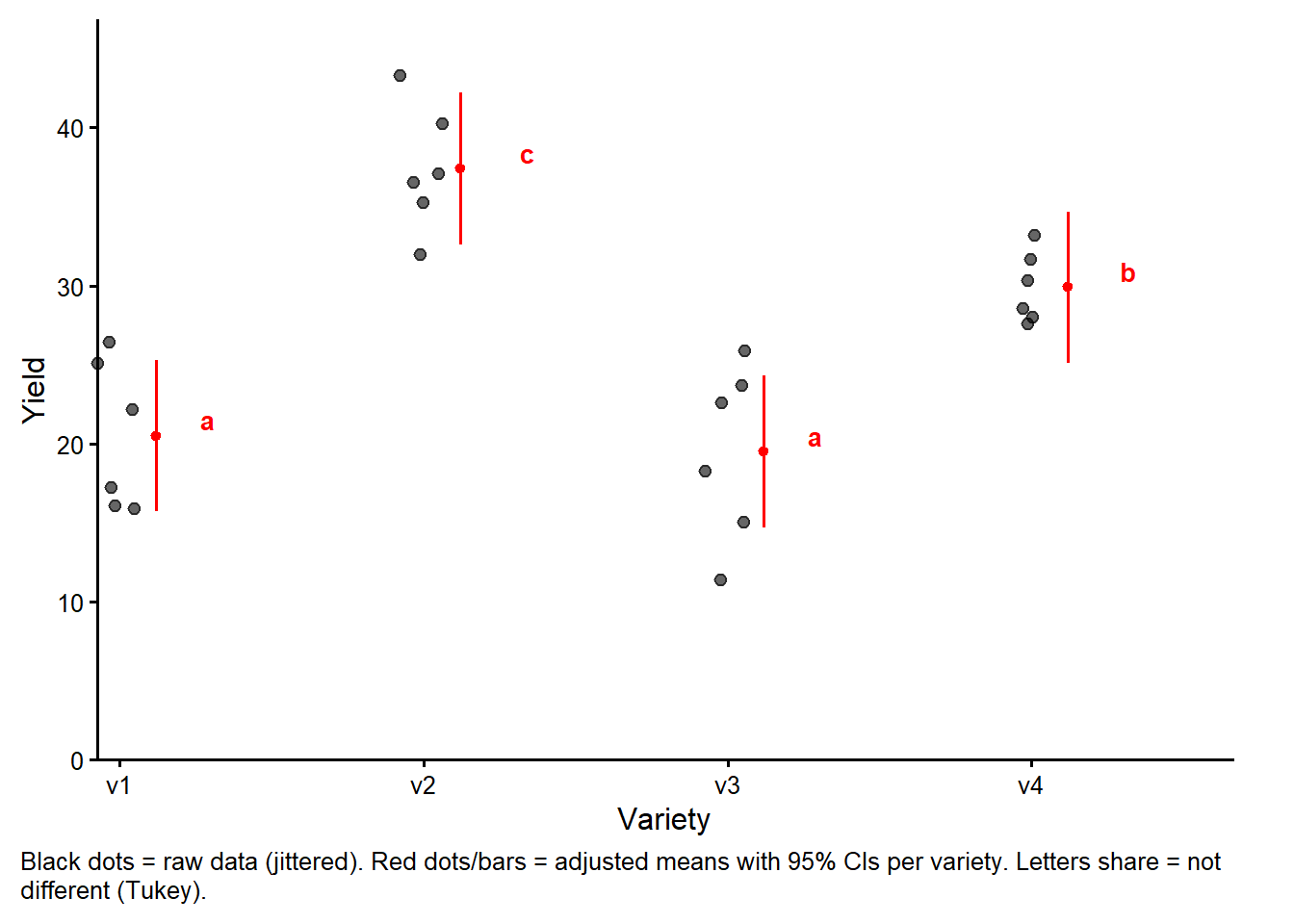
ข้อมูลที่มาทำได้เป็นงานวิจัยทดสอบผลผลิตเมลอน ตีพิมพ์ Mead et al. (1993, p.52) โดยการทดลองมีพันธุ์เมลอน 4 พันธุ์ แต่ละพันธุ์ได้รับการทดสอบในแปลงทดลองจำนวน 6 แปลง ออกแบบการทดสอบแบบ สุ่มสมบูรณ์ (CRD) จาก “Example 4.3” หนังสือ “Quantitative Methods in Biosciences (3402-420)” by Prof. Dr. Hans-Peter Piepho
ggplot(data = dat, aes(y = yield, x = variety)) +geom_point() +# scatter plotylim(0, NA) +# force y-axis to start at 0theme_classic() # clearer plot format
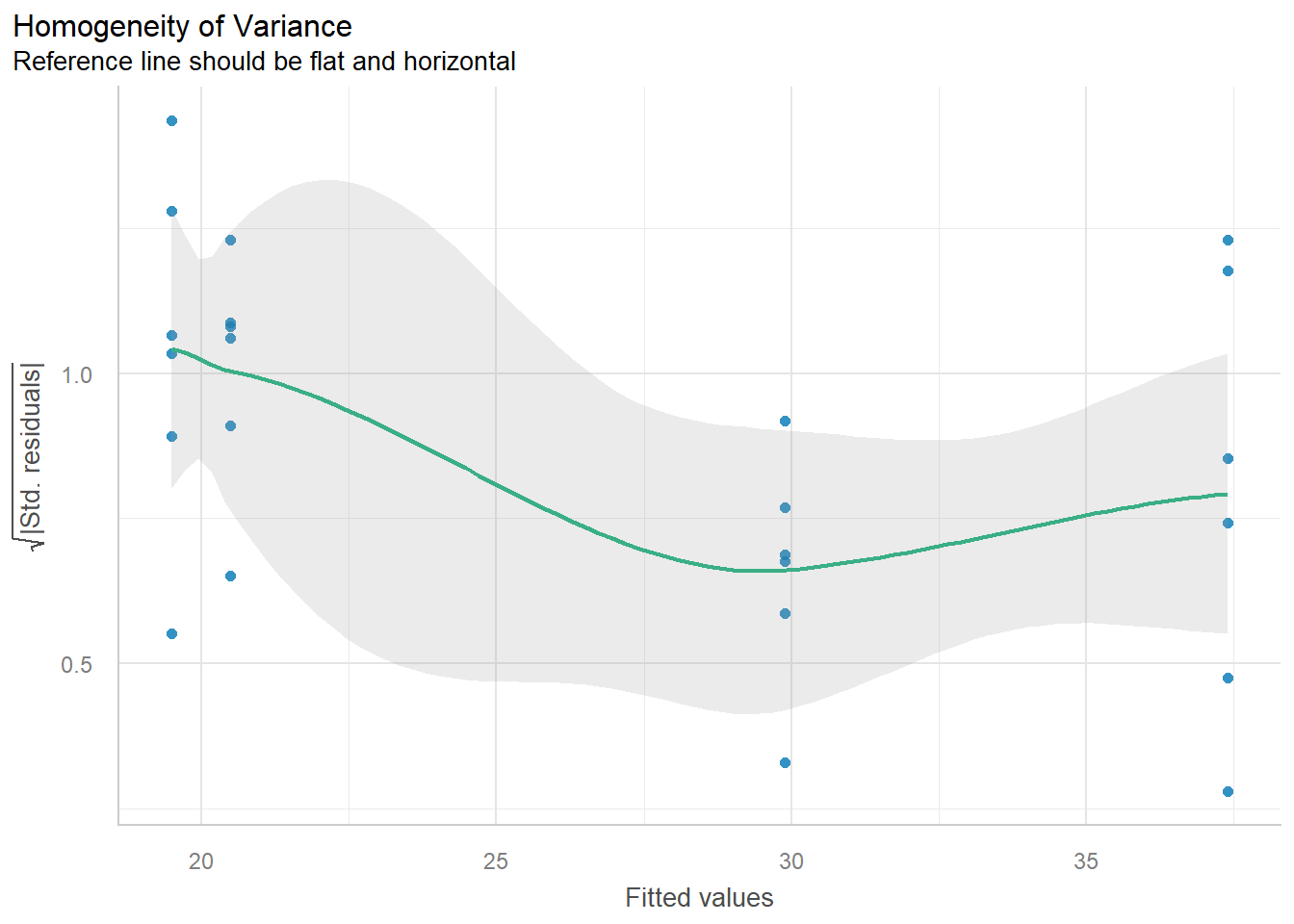
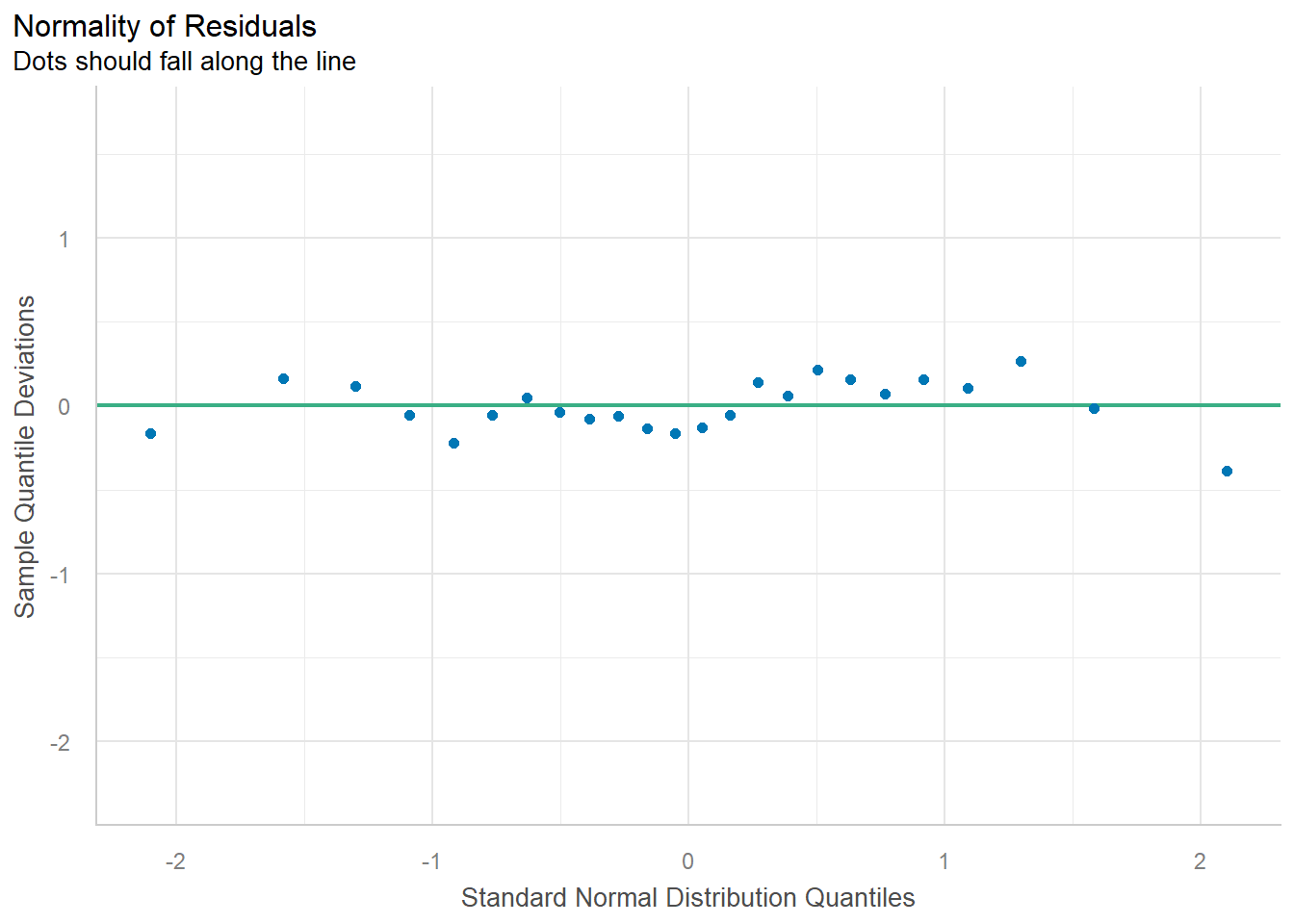
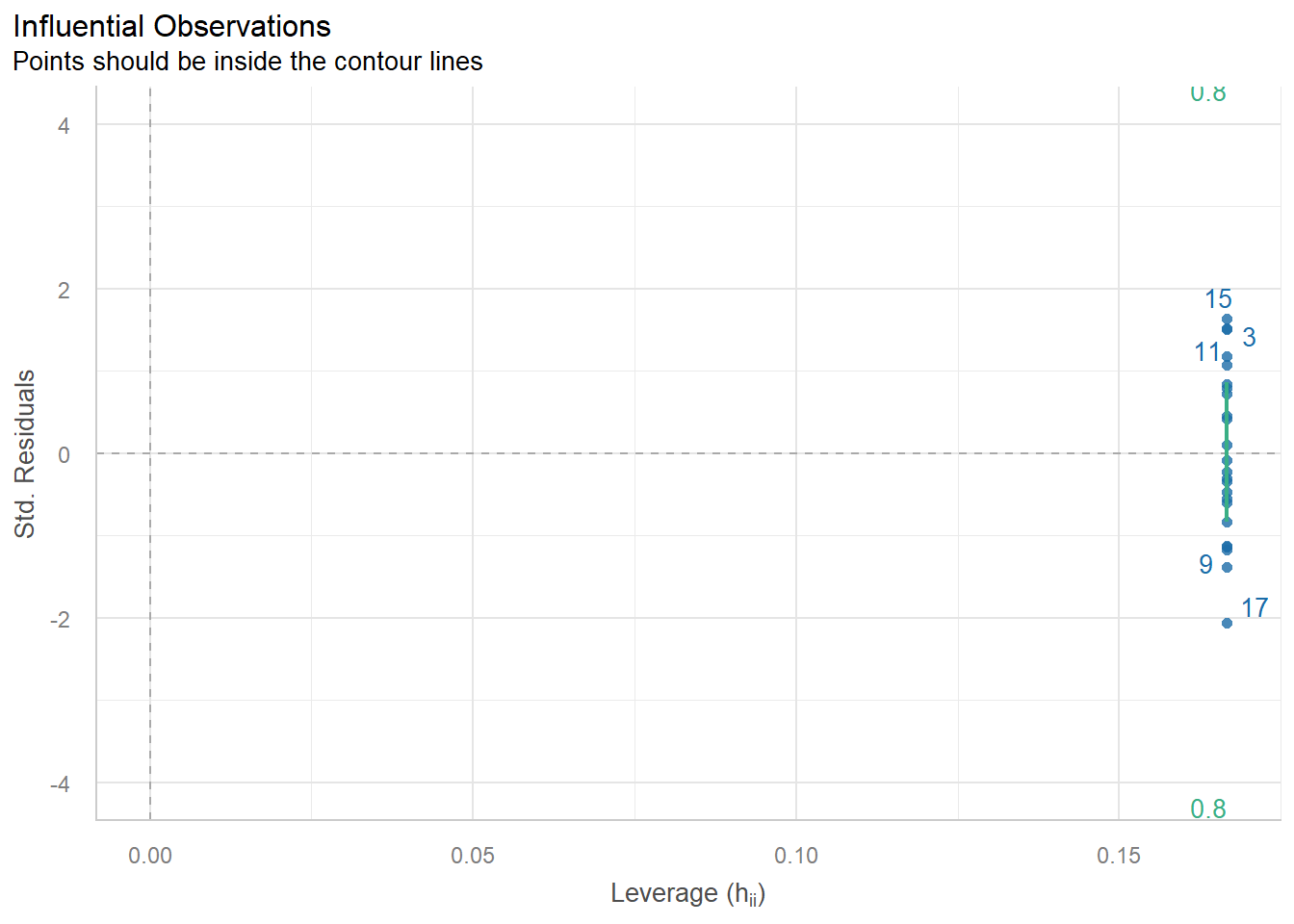
fit <-lm(yield ~ variety, data = dat)car::Anova(fit, type =3)
Sum Sq
Df
F value
Pr(>F)
(Intercept)
2519.0406
1
137.0335
0e+00
variety
1291.4771
3
23.4184
9e-07
Residuals
367.6531
20
NA
NA
ถ้าเป็น code แบบ classic ก็ใช้ aov(yield ~ variety, data = dat) ซึ่ง ถ้าเป็น ปัจจุบันตอนนี้ เราจะนิยมและปลอดภัยสุด หรือ ANOVA type จาก Data Science for Agriculture in R
In most cases it’s probably best to conduct a Type III ANOVA, e.g. via car::Anova(model, type = "III").
classic ANOVA
แบบ ANOVA จาก R base ก็ใช้ได้เช่นกัน นะ
aov.model <-aov(yield ~ variety, data = dat)summary(aov.model)
Df Sum Sq Mean Sq F value Pr(>F)
variety 3 1291.5 430.5 23.42 9.44e-07 ***
Residuals 20 367.7 18.4
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1